A Distributed Inference Engine for SmolLM with Rust and gRPC
Feb 25, 25Introduction
Language Model Inference at scale requires more effort than just having a working model on Hugging Face. Requests have to be load balanced across different inference nodes with seamless and easy to route communication for everyone to get their responses quickly, correctly, and easily.
System Overview
In broad strokes, their are two key parts of the system. The stack of containers running the language model (SmolLM), and the Rust client. gRPC is used for response streaming between the parts. First we will go over the Protobuf definition specifying the means of communication between these two parts.
Protobuf Definition
The protocol buffer (protobuf) for this project is relatively simple. The one remote procedure call (rpc) that we define has one specified request type (SmolLMReq) and one specified response type (SmolLMRes). SmolLMReq consists of one string, that represents the prompt for the language model.
SmolLMRes, however is a bit more complicated. Instead of just submitting one response per request, we instead stream our response to the Rust client as tokens are generated. Each SmolLMRes object sent back via the stream consists of three portions: a string representing the token, the token number (i.e. first token generated, second, etc.), and the token probability. As SmolLMRes objects are streamed back to the client, we can see token generations in real-time as opposed to having to wait for the whole response to be generated.
Container Stack
I made a stack of 5 containers via Docker Compose for serving the requests. Each of these containers is running SmolLM-135M. Then, we can expose a port for each of these containers (8080-8084) for client communication and streaming. After we defined our protobuf, we use this to generate our Python interfaces for the protobuf, from which we can define our Python server in each container. The yield keyword is used to send chunks of information back to the client in a streamed fashion.
Rust Client
Afterwards all of this, we just need to define our Rust client. I put a list of prompts in the jobs.txt file submit to our inference engine. For our Rust engine, we first can spawn an async task via tokio for each of the five containers in our stack. Each of these tasks will handle communication with the container in a nonblocking manner while still allowing us to do work in the main thread. Our load balancing technique is pretty simple. We use some vectors to track how many jobs are queued for each container and just submit the next job to the tokio task with the least amount of queued jobs at that moment in time. To actually handle job queueing, we use mpsc channels, which each consist of a transmitter and a receiver. In the main thread, after we use our load balancer to choose which container to submit a job to, we can send it over the channel with the trasmitter. Inside each of our async tokio tasks, the receiver will then process this job, send it to the container via a SmolLMReq, and print out the streamed responses. After this is done, it’ll just check if it has more prompts in the channel that it needs to receive and process. Note that our main thread requires a small loop at the end of submitting all the jobs to check if any of the async tasks are still working on any prompts; if we don’t do this check then our main thread just returns automatically and the spawned async tasks shut down too without actually handling the prompts.
Output Analysis
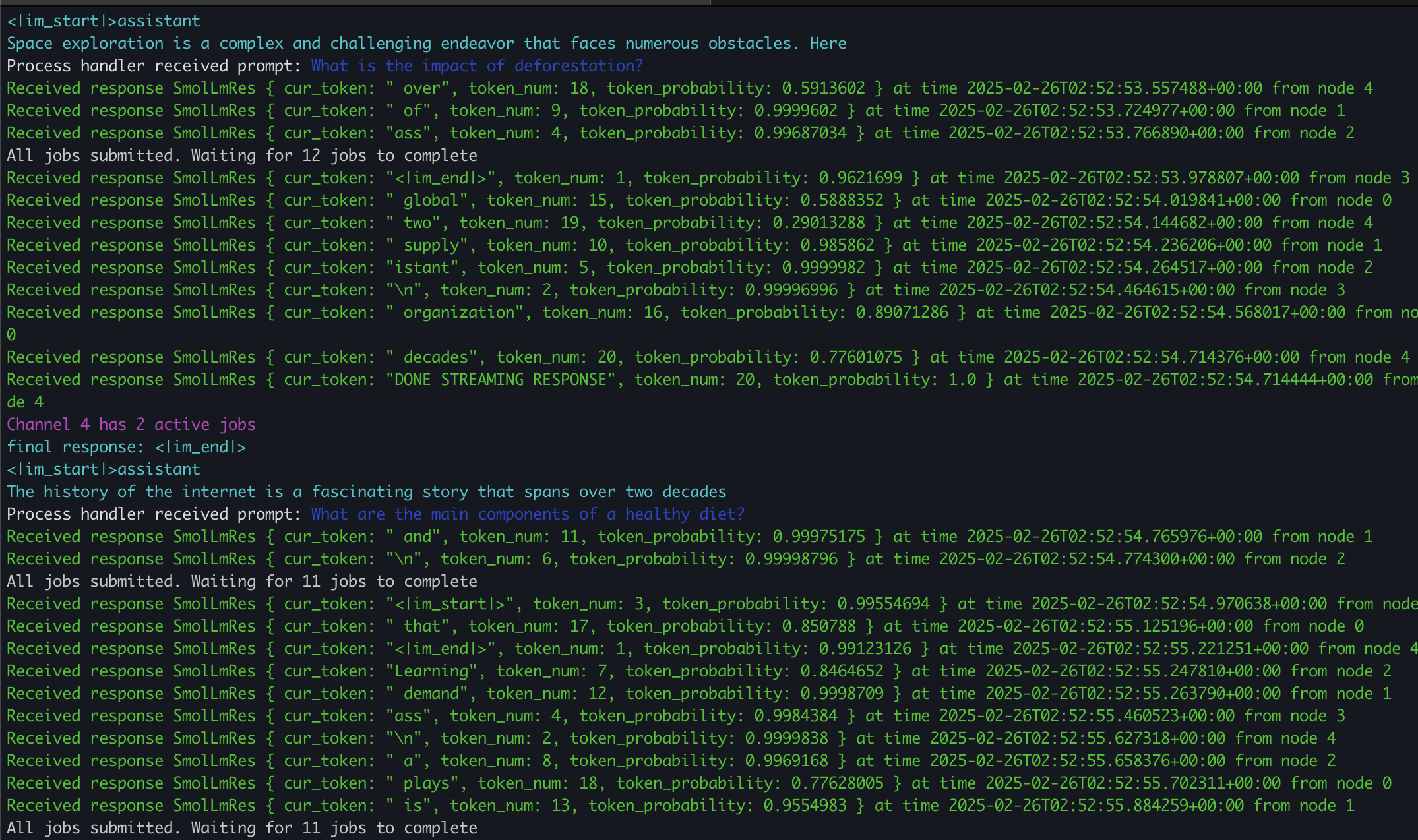
I wanted to make the output a little colorful just for show. Here’s some guidelines on the core components:
- Each green portion represents a token being streamed back from the client.
- Each dark blue portion represents when a new prompt starts being processed by a node.
- Each light blue portion represents the final SmolLM output for a given prompt.
- Each purple portion represents an update on the number of jobs either queued/in progress for a certain node after a job is completed.
Hope you found this interesting! Check out the github or email me if you want to talk about this project or suggest some changes!