Test-time Compute Algorithms for Diffusion Language Models
Mar 02, 25Introduction
Made at the 2025 Cognition, Etched, Mercor Test-time Compute Hackathon with @Parsa-Idehpour, @Nikita-Mounier. Happy to say we were finalists (top 6)! We plan to write a paper on this once it’s more fleshed out.
Basically all of the work in test-time compute since late 2024 has centered around the auto-regressive model architecture. Text diffusion models, on the other hand, have gained popularity recently for their bet on the opposite end of the spectrum. One can sample and re-sample tokens in any order without the need to backtrack progress.
About 36 hours before the hackathon, LLaDA was released on HuggingFace, which we are pretty sure is the first open-source, instruct tuned diffusion language model. This meant that for the first time it’s viable for open source researchers to test the performance of DLMs on modern benchmarks out the box.
As such, we decided to see if we could cleverly utilize inference-time compute in ways special to DLMs that could not be applied to standard autoregressive models (ARMs).
Overview of Test-Time Compute Strategy
Using the Qwen2.5 Math PRM, we wanted to steer chains of thoughts using stepwise process rewards. As such, we first implemented standard test-time compute algorithms like beam search on LLaDA, with which we observed around a 2x improvement over raw LLaDA on the abridged version of benchmarks like GSM 8K and MATH 500 that we tested.
However, this does not truly leverage the unique parts of diffusion language models that is not achievable with ARMs. The fact that you can remask and sample tokens in any order without backtracking later tokens is powerful; and allows for internal CoT steps to be altered without changing the ones that come after it. Combining this power with a PRM, we invented a technique called backmasking, which we believe is the first of its kind test time compute method leveraging the unique characteristics of diffusion language model.
LLaDA works in a semi-autoregressive fashion; you unmask new tokens in groupings called blocks, and as you pass through the model’s noising and denoising steps, you repeatedly generate tokens block by block.
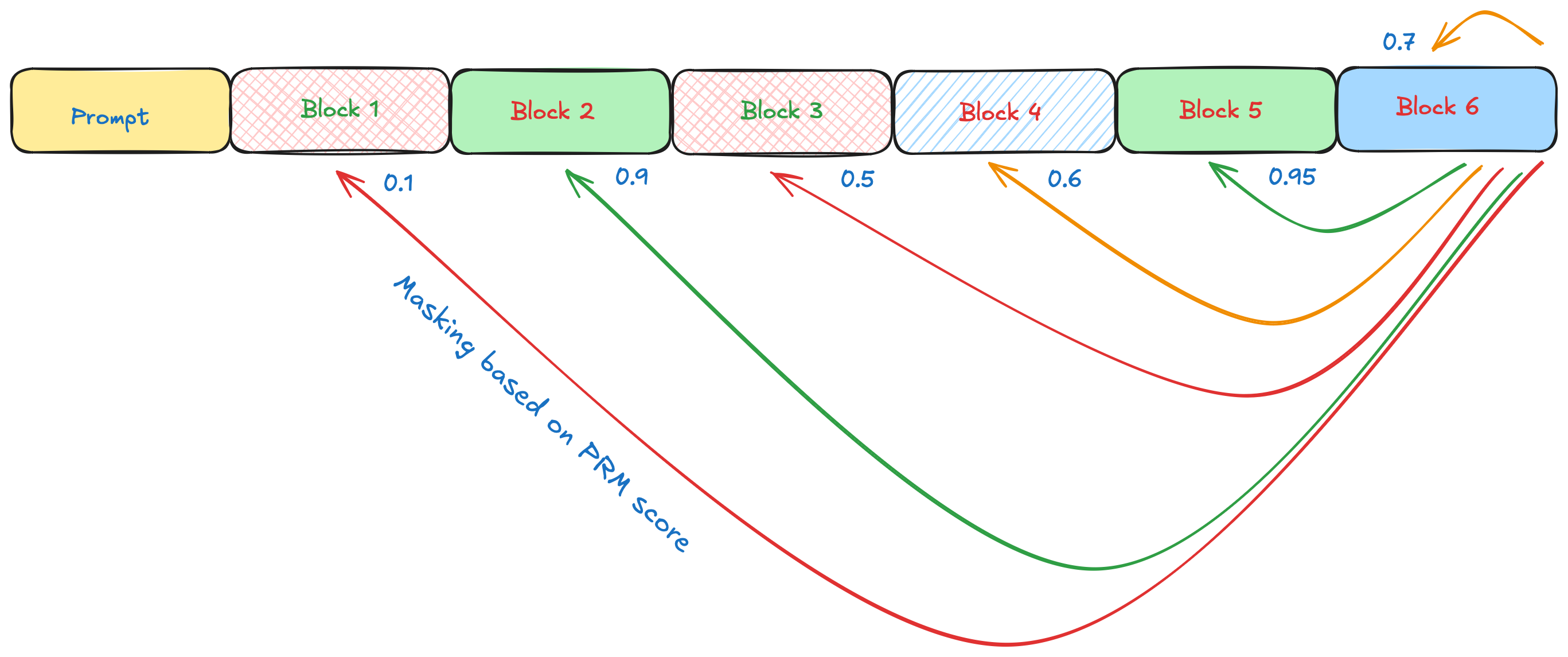
We interpret each block in a DLM as a step in a chain-of-thought for a model response, upon which we can apply a PRM. As blocks are demasked, we use our Qwen PRM to score each block. If a PRM score is below a threshold (hyperparameter), then we trigger the backmasking process, which consists of a few steps.
For each of the past blocks in a certain window (hyperparameter), we determine a backmasking frequency \(p=e^{-\alpha\cdot \text{PRM Score}}\). This means that for each block in the window, we mask remask random tokens in the block with proportion \(p\). The intuition behind this is that for low PRM score blocks, we remask at far higher proportions, and mask much less for high PRM score blocks. After each block has it’s remasked tokens, we conduct a global demasking process, meaning that instead of demasking these newly masked tokens in the same semiautoregressive fashion as the LLaDA model, we simply just demask all of the masked tokens in all of the blocks before handling the next block.
We can do this demasking in a best of N fashion by adding some Gumbel noise to our DLM demasking process, then conducting our global demasking process \(n\) times, and then just choosing the output with the highest average PRM score for the window. There are many variations on this method that can be conducted. For example, one can trigger PRM based remasking and global demasking every \(k\) blocks rather than triggering it on a PRM level. Additionally, instead of remasking tokens in each block randomly based on the proportion \(p\), one can also just select the tokens in the block whose logprob was the lowest, meaning it was the least confident about them. Here’s a nice diagram showing the process.
Conclusion
Me and my teammates hope to write a paper on this, so I will update this page when that is fully fleshed out. In the meantime, check out the github or email me if you want to talk about this project or suggest some changes!